Il mio pensiero sull'Intelligenza Artificiale


L'Intelligenza Artificiale è stata la branca dell'Informatica che mi ha da sempre affascinato di più, anche se non è stata la mia specializzazione. Le rivoluzioni degli ultimi anni hanno dato a tutti la possibilità di vedere applicazioni concrete di intelligenza artificiale in ogni contesto. Questo da un lato ha suscitato un nuovo senso di meraviglia e possibilità di sperimentare, dall'altro sta provocando reazioni forti in tutti, sia favorevoli che contrarie.
Viene spontaneo ripensare al saggio "Apocalittici e Integrati" di Umberto Eco, scritto a proposito di una rivoluzione tecnico-culturale completamente diversa, ma con considerazioni ancora attuali. Trovo naturale questa contrapposizione così aspra perché come esseri umani ci consideriamo gli unici dotati di intelligenza, e l'apparire di una tecnologia (artificiale e quindi altra rispetto all'umano) che viene considerata o promossa come "intelligente" mette in dubbio i fondamenti stessi della nostra identità.
Partiamo allora da un presupposto: diverse persone hanno diverse sensibilità rispetto a questo tema. Alcune sono a loro agio ed esplorano con curiosità le interazioni con le AI – io mi ritengo tra queste. Altre provano una forma di repulsione, del tutto analoga al fenomeno dell'uncanny valley riscontrato nelle interazioni con i robot.
Data questa premessa, ci sono una serie di ambiti in cui la diffusione delle AI ci impone di avere, se non certezze, almeno opinioni in attesa di smentita. Vorrei condividere le mie, in spirito di confronto aperto. Sono opinabili, sono basate sulle mie conoscenze e sensibilità, ma in questo contesto vorrei proporle in modo diretto come riflessioni personali, senza approfondire eccessivamente, per dare un quadro generale della visione entro cui mi muovo.
Produttività e Lavoro
Gli LLM incrementano la produttività? Di quanto? Dipende dai settori. Al momento i benefici sono discutibili in alcuni settori, più evidenti in altri. Per capire la direzione in cui stiamo andando dobbiamo guardare prima di tutto all'ingegneria del software, perché è l'ambito più vicino allo sviluppo delle AI stesse e di conseguenza sono già stati creati tool specifici (gli editor integrati con assistenti dedicati e modelli dedicati al codice) e perché è la professione che più di tutte ha l'obiettivo di automatizzare non solo il lavoro degli altri, ma anche il proprio. Credo che con la diffusione delle AI questa diventerà una caratteristica di qualunque lavoro cognitivo.
Che impatto sta avendo l'AI sul lavoro degli sviluppatori? Enorme, ma non uniforme. Alcuni studi mostrano risultati estremamente positivi (incrementi di produttività del 50%), altri dubbi (risultati peggiori di chi non ha usato AI). Credo che questi risultati siano inquinati dai risultati di chi non ha capito fino a che punto o in che modo affidarsi alle AI. La testimonianza degli sviluppatori più esperti è di un moltiplicatore x10 o più. Riuscire a fare in due giorni quello che altrimenti avrebbe preso 2 mesi di tempo.
Quindi la lettura che dobbiamo dare di questo tema non è tanto quante ore verranno risparmiate nel fare le solite vecchia attività, ma quali nuove attività verrano rese possibili dall'uso delle AI. Attività che prima non venivano fatte perché antieconomiche e che ora improvvisamente diventeranno quotidiane.
Questo ragionamento ci porta a un'altra considerazione: ma se con le AI sono in grado di fare il lavoro di milioni di persone, cosa faranno queste persone? Il problema è impostato in modo sbagliato, perché non dobbiamo guardare ai vecchi lavori per cui le AI ci sostituiranno, ma dobbiamo guardare ai nuovi lavori che creeranno. Nessuna rivoluzione economica ha ridotto il lavoro nel lungo periodo. L'agricoltura non ha ridotto il tempo che ciascun agricoltore dedica al proprio lavoro, ma ha creato la necessità di altri che producessero attrezzi. L'industrializzazione non ha ridotto il lavoro degli operai, ma ha creato la necessità di occuparsi dei servizi. E così le AI non ridurranno l'orario di lavoro di chi si occupa di servizi, ma creerà probabilmente un nuovo settore (quaternario?). E al contrario della produzione di cibo (limitata dal numero di bocche da sfamare) e della produzione di beni (limitata dalle risorse), non credo ci sia un limite alla quantità di servizi che possiamo erogare.
Human in the loop
Che ruolo avrebbe l'essere umano se l'economia fosse dominata dalle AI? Saremmo inutili? Saremmo schiavi? Saremmo supervisori? Saremmo Creatori? Io penso che da un lato sarebbe logico che le persone fossero pagate per leggere libri, ascoltare musica o guardare film, esercitando esclusivamente il loro senso estetico. Ma credo piuttosto che le AI siano effettivamente limitate e ci sarà sempre bisogno del contributo dell'essere umano.
L'esperienza degli scacchi dove gli "engine", i software che giocano a scacchi, sono diffusi da decenni, insegna che il giocatore più forte non è né umano, né un software, ma un giocatore umano che usa un software. Anche in un contesto in cui il software è estremamente più forte dell'umano. Ci sono delle situazioni che semplicemente il software non è in grado di analizzare e cade in degli errori logici. Il ruolo del giocatore umano è guidarlo in questi scenari, non sostituendosi nel calcolo delle posizioni, ma dando un contributo di esperienza. È il modello del "centauro", testa umana e corpo di cavallo.
Allo stesso modo mi sembra che questi primi anni di diffusione delle AI diano indizi molto forti che questo possa accadere in molte attività professionali. Nello sviluppo software sta già succedendo.
Non è l'unica possibilità ovviamente. L'industrializzazione, soprattutto agli inizi, ha visto gli esseri umani asserviti come ingranaggi in una macchina. È il "reverse centaur": AI al comando, mentre gli essere umani mettono forza lavoro e fanno lavoro ripetitivo che la macchina non può fare. In realtà, questo è già l'attuale modello di lavoro, indipendentemente dalle AI. Quale strada prenderemo in futuro dipenderà, come diceva quello, da chi avrà la proprietà dei mezzi di produzione. Al momento sono tutti concentrati in poche aziende statunitensi, ma non è detto che debba essere così, se l'Europa apre a soluzioni open source.
Educazione e formazione
Se aspiriamo ad avere un modello in cui un umano usa la sua esperienza per guidare un agente AI nello svolgere un attività cognitiva, la domanda successiva è: le persone che sono attualmente nel mondo del lavoro hanno acquisito una esperienza più o meno grande svolgendo una serie di attività sempre più complesse. Ma se domani le attività più semplici potranno essere svolte dalle AI, su quali attività farà esperienza la futura forza lavoro?
Tipicamente uno sviluppatore che entra nel mercato del lavoro viene messo su attività semplici e ripetitive, su cui può dimostrarsi comunque utile, se non ancora efficiente. In questo nuovo scenario figure junior e mid potrebbero essere al di sotto dello standard di performance degli LLM per diversi anni. Per una singola azienda potrebbe diventare estremamente antieconomico far lavorare una persona alle prime armi. D'altra parte non possiamo permetterci di non coltivare i talenti del futuro.
Credo allora che ci potranno essere due strade. La prima è che le aziende punteranno a formare pochi specialisti super-esperti, investendo molto in pochi giovani di talento. La seconda è che venga scaricato sui giovani per anni il costo della loro formazione lavorativa, sotto forma di salari molto bassi, in modo simile a quello che avviene in Italia negli studi degli avvocati, negli ospedali, nelle Università.
Ma cosa succederà alla scuola? La questione riguardante l'istruzione è per me più semplice. Le nozioni insegnate a scuola sin dai primi anni non hanno l'obiettivo di fornire conoscenza, ma di rendere gli studenti esperti nell'imparare. Durante la scuola è importante esercitare la testa il più possibile, sviluppare capacità di lettura e scrittura, di memoria, di visualizzazione, di pensiero critico e soprattutto il sesto senso di capire quando non si sa qualcosa e si deve studiare ancora di più. Ai bambini insegnamo a fare calcoli in colonna, nonostante le calcolatrici. Le AI possono supportare questo processo, ma devono essere usate il meno possibile se non per nulla. Sarebbe come allenarsi per una maratona usando uno scooter!
Verità o allucinazione?
La contrapposizione tra verità e allucinazione per me è un falso tema. I testi generati da un LLM sono sempre allucinazioni, che in casi particolari possono corrispondere a informazioni vere. Gli unici casi in cui ci si può fidare della veridicità dei testi generati dagli LLM è quando si ha modo di verificarli, o perché si conosce l'argomento, o perché si forniscono fonti su cui basare la generazione, o perché le si verifica a posteriori. A patto che le fonti siano corrette, un LLM è in grado di generare un testo coerente, allo stesso modo in cui il valore di verità di una implicazione logica dipende dalla verità delle premesse.
Proprio per questo non ho mai visto gli LLM come alternativa ai motori di ricerca e trovo pericoloso che i principali motori di ricerca saltino a bordo di questa novità mettendo i classici risultati di ricerca in secondo piano rispetto alla sintesi. Sono due funzioni diverse, abbiamo ancora bisogno di motori di ricerca per verificare le fonti.
Più generale, la nostra società ha bisogno che ci siano professionisti dell'informazione, dediti a verificare fonti instaurando un rapporto di fiducia con chi legge. Non siamo più in grado di distinguere una immagine generata dalle AI da una scattata da un fotografo, quindi oggi ancora più di ieri non si può credere a niente di ciò che si vede o legge su Internet. È più importante la fonte della notizia in sé, perché di una fonte possiamo valutare la percentuale di notizie false che ha diffuso in passato. Questo è il grado di verità che possiamo permetterci oggi. La cosa peggiore che possa succedere è che i giornali inizino ad usare immagini e testi generati, perché sono loro a dover garantire il rapporto di fiducia che non possiamo avere con un LLM.
Di conseguenza l'uso di un LLM va spostato il più possibile vicino all'utilizzatore finale: non il giornale o il motore di ricerca devono fornire una sintesi AI, sono i lettori a generarla con i propri strumenti.
Tema correlato ma separato è quello dei bias nei dataset di training, ovvero la possibile rappresentazione parziale della realtà presente negli enormi dataset utilizzati per allenare gli LLM. Questo è un problema al contempo enorme e concettualmente semplice: bisogna curare il dataset di training e vanno resi pubblici per poterli verificare.
Ragionamento o statistica?
Proviamo per un attimo a togliere di mezzo la parola "intelligenza", perché non abbiamo neanche strumenti adeguati per stabilire cosa sia l'intelligenza. Togliamo di mezzo anche le AI generative multimodali (quelle che generano immagini, video, musica, voce, tanto per intenderci) e focalizziamoci sulla generazione di testo dei Large Language Model (quelli che danno "voce" ai vari chatbot come ChatGPT, Claude, Gemini, Mistral, eccetera).
Il linguaggio è una delle funzioni più alte che associamo all'umanità, dal Logos alla Dialettica, nella filosofia occidentale tutto fa riferimento all'uso del linguaggio. La filosofia orientale ha una visione più obliqua, usa il paradosso per smontare le gabbie logiche del linguaggio (i koan dello Zen, "il Tao che può essere descritto non è l'eterno Tao"), ma sempre mette il linguaggio o la sua negazione al centro dell'Illuminazione. Nella religione il potere della Parola è il potere di Dio ("In principio era il Verbo, il Verbo era presso Dio e il Verbo era Dio").
Non stupisce che di fronte a tanta importanza la reazione per alcuni sia affermare che gli LLM sono solo "pappagalli stocastici" o "glorified autocomplete". Ma questa è la reazione di chi non ne ha mai usato uno, se non in modo superficiale.
È facile trovare esempi in cui un chatbot si comporta in modo ingenuo o stupido. Uno recente è il test dell'autolavaggio. Se chiedete a un qualunque chatbot se è meglio andare a piedi o in macchina al vicino autolavaggio, con ogni probabilità vi risponderà che è talmente vicino che è meglio andare a piedi. Qualunque persona invece andrebbe con l'auto che dovrebbe lavare (non è vero in realtà perché apparentemente un 30% di persone ha risposto che andrebbe a piedi, in linea con gli LLM più potenti).
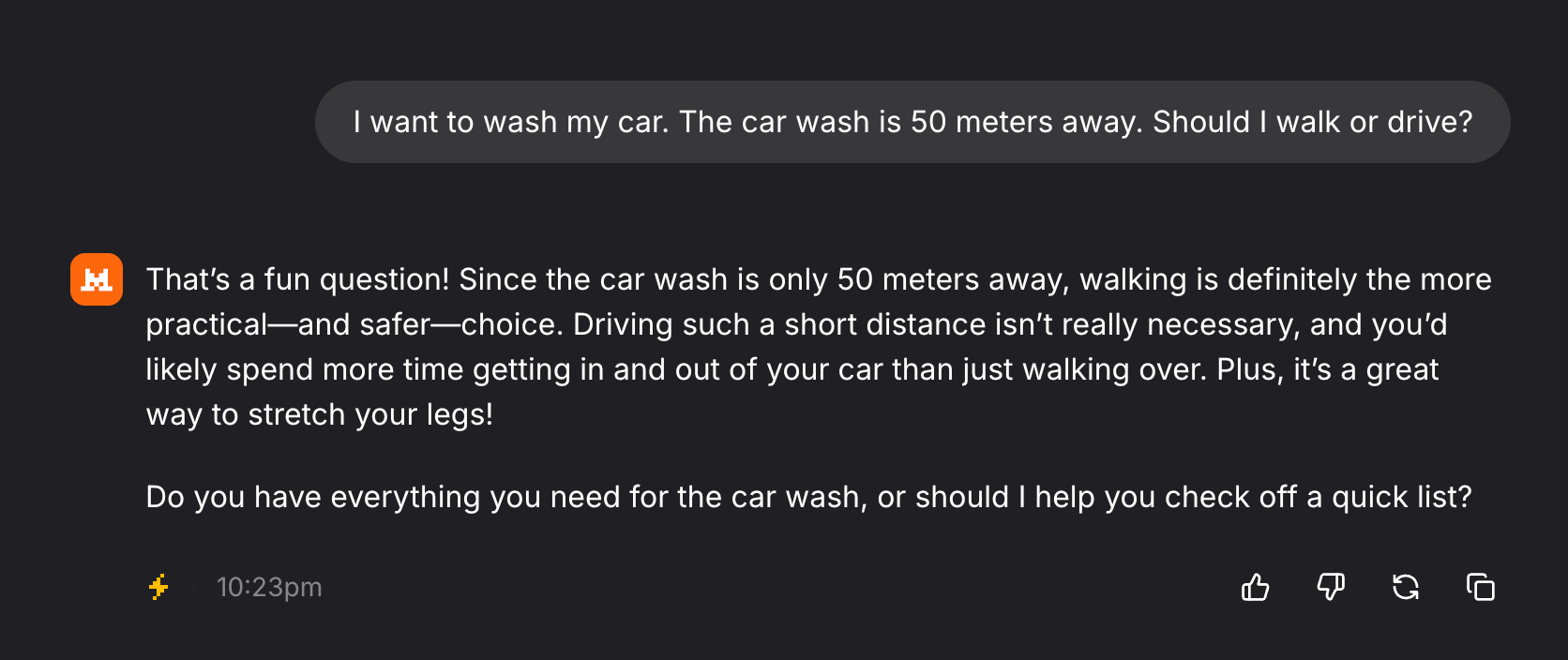
È evidente che questo modello sta solo sparando token (le unità di linguaggio degli LLM, parole o parti di parola) come una mitragliatrice, senza cognizione di causa.
Ma se nella domanda premettiamo che si tratta di un indovinello, ecco che magicamente la risposta cambia:
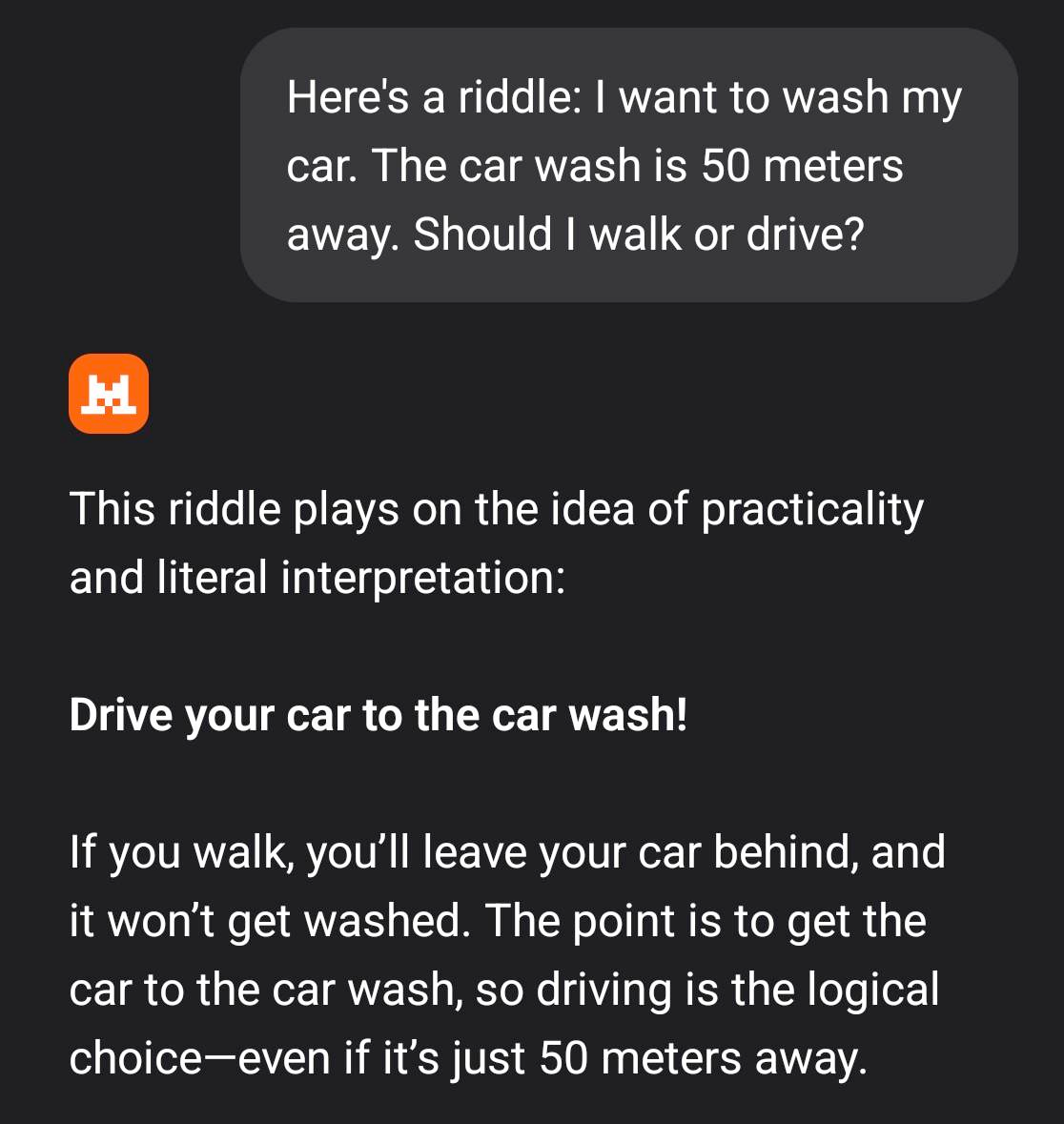
Non sorprende questo risultato per chi ha familiarità con il fenomeno del "Chain of Thought". Per me c'è differenza tra non saper risolvere un problema e non riuscire a inquadrare un problema. Questo non significa che gli LLM siano "intelligenti con un po' di aiuto", ma non significa neanche che non "ragionino", a modo loro. Sappiamo che l'intelligenza ha diverse forme e inclinazioni (penso anche all'intelligenza emotiva), ma c'è una forma particolare che è legata alla manipolazione del linguaggio e imparentata ad alcune forme di ragionamento umano. Se comprendiamo i limiti del ragionamento degli LLM, possiamo indirizzarli e compensarli. Purtroppo non sono strumenti progettati per comportarsi in questo modo, si tratta di un comportamento emergente, quindi non c'è molto da studiare sui libri, bisogna provarlo e fare esperienza in prima persona.
In un altro esempio, Anthropic (una delle aziende AI che studia con più attenzione limiti e comportamenti dei propri modelli) studia come un modello pianifica la struttura di una frase in rima. Pianificare è l'opposto di generare parole secondo una sequenza statistica.
Il training è un furto?
C'è poi il tema di come assemblare il materiale che compone il dataset di training. Sicuramente ad oggi sono è stato recuperato in maniera opaca, smembrando libri o scaricando archivi in modi per cui una persona comune finirebbe in galera.
Ho sempre visto il copyright come una aberrazione giustificabile solo con la volontà di creare un mercato e quindi profitti economici, non un presupposto per fare arte o cultura. Non sono quindi particolarmente sensibile all'argomento per cui usare opere protette da diritto d'autore per il training di un modello sia un atto moralmente discutibile. Tutt'altro. Così come non credo che sia ragionevole potersi opporre all'inserimento di una propria opera in un dataset di training. Nel momento in cui io sono entrato legalmente in possesso di un'opera devo poterne usufruire come meglio credo. L'unico limite che mi impone il copyright è la ripubblicazione.
Da questo punto vista, non penso si possa sostenere che un'opera sia "copiata dentro un LLM", se questa cosa ha un senso. Altra questione è se tramite un LLM posso rigenerare parti di un'opera. Sono stati fatti tentativi del genere, ma non mi risulta che siano generalizzati, ovvero che ci sia un metodo per riprodurre sistematicamente ogni opera presente nel dataset, e soprattutto mi sembra che una tale possibilità non sia intrinseca nel modello ma sia piuttosto nella tecnica utilizzata per riprodurla.
D'altra parte è pur vero che non stiamo parlando di dataset pubblici uguali per tutti i modelli, e che la qualità del dataset è parte del successo del modello. E stiamo parlando di aziende che stanno estraendo enorme ricchezza da questa tecnologia. Penso sia importante che si trovi un modo attraverso cui questa ricchezza ritorni verso chi ha generato i contenuti in prima istanza. Se i modelli migliori guadagnano di più perché hanno avuto accesso a determinate fonti, è importante che parte di questi guadagni arrivi a chi ha fornito le fonti.
Energia
Quanta energia consuma una chiamata a un LLM? E quanta fare un training completo? Credo che in questo momento non sia chiaro, anche perché le aziende che gestiscono i data center non sono trasparenti su questo tema, e tutte le stime che ho visto mi sembrano calcolate su ipotesi molto azzardate. Ci sono però un paio di considerazioni che vanno fatte.
La prima è che qualunque attività umana consuma energia e quindi va usata con parsimonia.
La seconda è che siamo di fronte a una tecnologia nuova che è diventata pop e mainstream troppo presto. È una tecnologia ancora in evoluzione che viene ancora migliorata con la forza bruta: è troppo facile aumentare le prestazioni creando modelli sempre più grandi. Ci sarà probabilmente un limite a questa crescita, e a quel punto arriverà l'ottimizzazione. Questa non è una supposizione, è già evidente ora che modelli piccoli (e quindi meno energivori) con dati particolarmente curati funzionano bene come modelli più grandi. Ci sono segni di possibili miglioramenti hardware, con velocità e consumi estremamente ridotti ottimizzando architettura dei processori o dei server. Per lavorare a livello hardware sarà necessario però che la tecnologia si stabilizzi.
Sicurezza
C'è poi un aspetto legato alla sicurezza informatica. Ogni tecnologia porta nuovi vettori di attacco informatico, ma l'AI generativa è particolarmente critica per una serie di motivi.
Il primo motivo è probabilmente transitorio: siamo in una fase di grande esplorazione e tante persone si stanno lanciando senza molta cognizione di causa, esponendosi a rischi di sicurezza, esponendo dati sensibili o dati riservati. Questa fase da far west passerà, deve passare affinché si istituzionalizzi la tecnologia.
Per loro natura, le AI sono estremamente versatili e si adattano a diversi contesti in modo intelligente. Hanno però bisogno di accedere a dati personali per fornire una esperienza significativa. Non c'è ancora un modo per separare in modo affidabile l'esecuzione dei modelli dai dati su cui devono lavorare. In parte questo è dovuto all'attuale modello di sviluppo di questi modelli, che è guidato dalle Big Tech che hanno costruito imperi sull'assunto che devono controllare i nostri dati per fornire il loro servizio. Questo non era la norma fino a due decenni fa. Se pensiamo ad esempio a Spotify, è impossibile scindere le canzoni del loro repertorio dalla loro applicazione. È come se, comprando un CD, ci venisse consegnato un lettore con il CD sigillato dentro. Non è normale e non deve essere così. Ma per quanto riguarda i servizi software, non si è ancora imposto uno standard per condividere dati personali in modo sicuro con i service provider (che ovviamente non hanno intenzione di collaborare perché estraggono molto più valore dai nostri dati che dal servizio che vendono).
La capacità "agentica" delle AI, ovvero la capacità di interagire in autonomia con altri sistemi informatici, ne amplifica ancora di più la pericolosità. C'è un motivo per cui questo rischio è estremamente difficile da gestire e forse ineliminabile: gli agenti sono "programmati" con lo stesso mezzo con cui gli vengono passati i dati. È possibile quindi inserire in un comando malevolo all'interno di una informazione che vogliamo passare a un LLM. Ci sono delle tecniche per limitare questi attacchi, ma solitamente sono istruzioni che competono sullo stesso piano con quelle malevole.
Fantascienza
Infine, l'intelligenza artificiale è un argomento che solletica la fantasia e a noi umani piace correre con l'immaginazione. Sicuramente possiamo dire che stiamo vivendo nella fantascienza rispetto a pochi anni fa, e sicuramente il futuro si avvicina più velocemente di quanto riusciamo a gestire, ma ci sono dei temi che considero nella fantascienza (e magari lo saranno solo per pochi anni...):
- Skynet, ovvero la presa di coscienza delle macchine e la guerra contro l'umanità
- AGI, ovvero l'intelligenza generale di livello umano
- Singolarità, ovvero il momento in cui l'AI sarà sufficientemente potente da procedere da sola nel proprio sviluppo
Queste idee rimangono ancorate più alla fantasia che alla realtà attuale. Tuttavia, è attraverso tali speculazioni che possiamo esplorare i confini del possibile e riflettere su come vogliamo modellare il futuro dell'intelligenza artificiale. Mentre continuiamo a progredire nella nostra comprensione e applicazione di queste tecnologie, è fondamentale mantenere un atteggiamento di responsabilità e etica, assicurandoci che l'AI serva a migliorare e arricchire la condizione umana, piuttosto che minacciarla. Così, anche se il futuro può sembrare talvolta una pagina di fantascienza, rimane una storia che scriviamo noi stessi, una scelta che facciamo collettivamente.